Review: The Science of Managing Our Digital Stuff by Ofer Bergman and Steve Whittaker
For a long time I've held this conviction that hierarchical file systems are a disaster. Over the years, there have been many attempts at building systems which avoided them: the entire hypermedia lineage from Vannevar Bush's Memex with trails, through Ted Nelson’s work, and on to efforts like HyperCard, along with completely different approaches like the Canon Cat (and related, Archy) and Lifestreams. The common motivation seems to be that nested folders are a bad match for human thought.
We sought to reduce the influence of hierarchical directories and conventional files (which we see as large lumps with stuck names in fixed places, with compulsory gratuitous naming — unsuited to overlap, interpenetration, rich connectivity, reasonable backtracking, and most human thinking and creative work.)
It’s hard not to disagree — I’m relatively fastidious with my organization and my home folder is still full of incomprehensible structures accumulated over the years, not dissimilar to this XKCD comic:
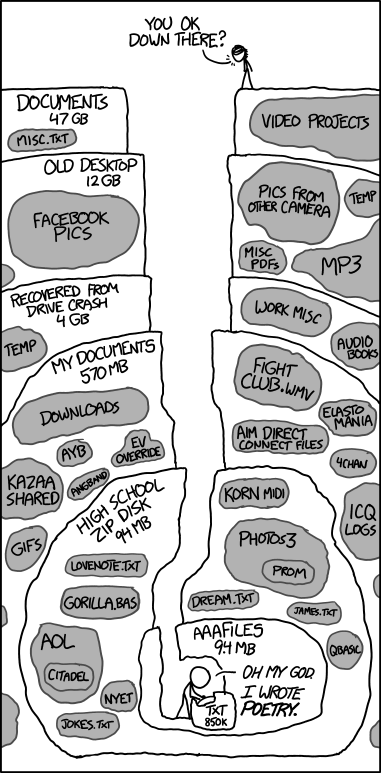
However, history has not been kind to these projects — I’ve tried a few myself and they’re okay for a while, but I keep coming back to traditional systems, despite their flaws. Desktop operating systems are still based around folders, more Web apps and mobile apps use a “simulated” files and folders representation, to the point where iOS 11 now adds a "Files" app avoided for the previous ten releases.
In a way, this shouldn't be surprising. The Lindy Effect tells us that the longer something non-perishable, like an idea, has been around, the longer its expected lifespan. There’s clearly something powerful behind files and folders, and a thorough analysis of why might give us a framework by which to understand improvements and alternatives. I was stuck without a clear path forwards until I discovered the fantastic book The Science of Managing Our Digital Stuff by Ofer Bergman and Steve Whittaker. The book is a summary of the work done in the space of Personal Information Management (PIM) over the past few years, including many studies designed by themselves. From the blurb:
Bergman and Whittaker report that many of us use hierarchical folders for our personal digital organizing. Critics of this method point out that information is hidden from sight in folders that are often within other folders so that we have to remember the exact location of information to access it. Because of this, information scientists suggest other methods: search, more flexible than navigating folders; tags, which allow multiple categorizations; and group information management. Yet Bergman and Whittaker have found in their pioneering PIM research that these other methods that work best for public information management don’t work as well for personal information management.
From the book:
This book provides a scientific understanding of how we select, organize, and access such personal collections. Personal information management (PIM) is the process by which individuals curate their personal data in order to reaccess that data later. Curation involves three distinct processes: how we make decisions about what personal information to keep, how we organize that kept data, and the strategies by which we access it later.
A poorly designed PIM system can result in "lost personal data”, “large, disorganized personal collections of unclear value”, and “failing to deal with time-sensitive information that requires action”. So far, so good. However, there’s a fundamental tension at the heart of things:
Choosing appropriate folder organization and labels therefore requires people to predict exactly how they will be thinking about particular information at the time that they need to retrieve it. Predicting future retrieval context is difficult, because there are usually multiple ways that a file can be categorized, such as by author, topic, date or project. The inability to accurately predict how one will think about information in the future makes it more likely that future retrieval will fail.
After walking through a number of alternatives to folders (search, tagging, group management) and showing that in user studies they don’t perform as well as folders, they get to the crux of their argument. Navigating folders is a spatial task, rather than a linguistic one like search or tags, which uses a different part of the brain:
Throughout millions of years of evolution, humans have developed mechanisms that allow them to retrieve an item from a specific location (be it real of virtual) by navigating the path that they first followed when storing that information. These deep-rooted neurological biases lead to automatic activation of location-related routines, which have minimal reliance on linguistic processing, leaving the language system available for other tasks.
PIM systems have a purpose and should be measured and evaluated as such. This gives us a framework by which to start comparing and improving on the traditional folder structure, as they do in the latter part of the book. One suggestion, which I very much agree with, is to get rid of application specific storage locations:
Documents relating to a given project are stored in one folder hierarchy (e.g., in My Documents), emails in a separate mailbox hierarchy, and favorite websites in yet another browser-related hierarchy…Although the additional structure solution allows users to work in an integrated project environment, it requires managing yet another structure and may increase cognitive complexity. As well as the additional requirement to create a new structure, the user now has yet another retrieval location to maintain and remember.
The book also leaves open the question of how to manage the interface between public or group information management, where search, hyperlinks, and tags do quite well, and the spatial world of PIM. Perhaps systems should be designed to respect the boundary: shared work drives, like Google Drive, shouldn’t have a shared folder structure but should be tagged and linked (which are shown to work well in group settings and novel content). Individuals can then pull those resources locally, with a stable location that they can navigate to when they need to exploit them.
There are some interesting technologies not evaluated that I would have loved to have seen in the book. The Plan 9 style unioned directory structure, and whether that helps or hinders spatial navigation (I feel like it would help, as traditional directories mix orthogonal concerns, like which physical drive the data is stored on). I would also love to have seen an in-depth discussion of Zooming User Interfaces such as Pad. They have their own issues (a good overview here) but proponents did clearly understand the neurological processes behind spatial navigation:
We can find things in such a planning room [a room dedicated to project planning where the walls are covered in sticky notes, photos etc.] because we tend to remember landmarks and relative position. “The stuff about marketing is on the right wall, sort of lower down near the far corner,” someone might tell you. On another occasion, you go right to a particular document because you remember that it is just to the left of the orange piece of paper that Aviva put up.
— Jeff Raskin, The Human Interface
All of which is fascinating, but the real breakthrough realisation for me came with this section:
The main aim of information item classification in PIM is not to externalize our internal representation of these items (Hsieh et al. 2008) or to fully describe them, as implied by Civan et al. (2008), but to support easy, fast, and efficient retrieval.
Novel information management systems need to understand that they are a tool to serve a purpose and conduct usability studies to ensure that they're achieving them. The Lindy Effect is strong: files and folders have been around for a long time, and their staying power is testament to how well they achieve their task. Future PIM proposals will do well to internalise this and look to build on their strengths while addressing current weaknesses.